GSoC 2018 - Week - 7


Week 6 of the GSoC coding period is completed successfully. GSoC (Google Summer of Code) is a global program focused on bringing more student developers into open source software development. Students work with an open source organization on a 3-month programming project during their break from school.
Project Abstract
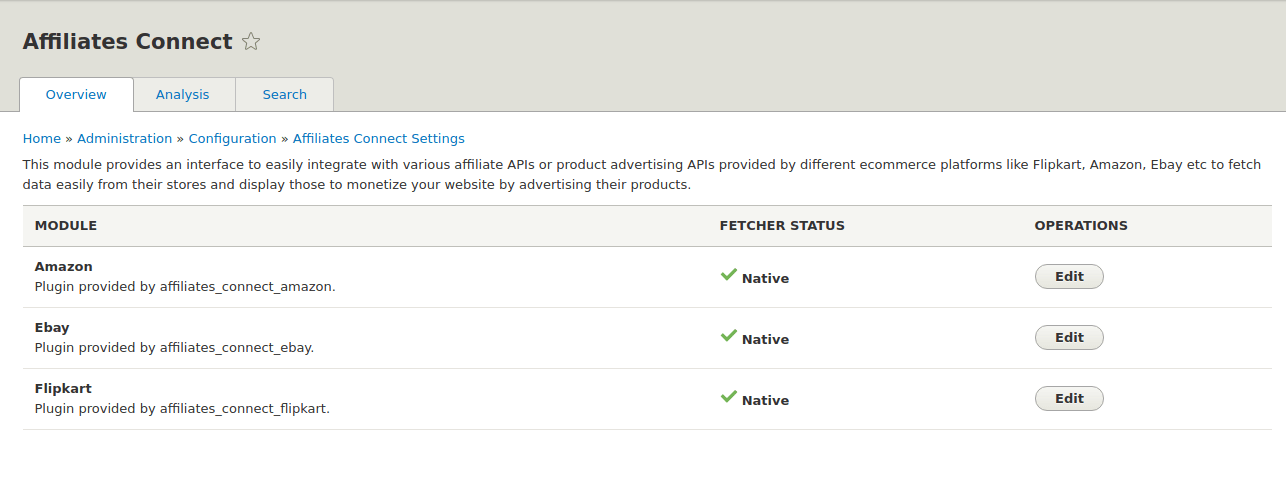
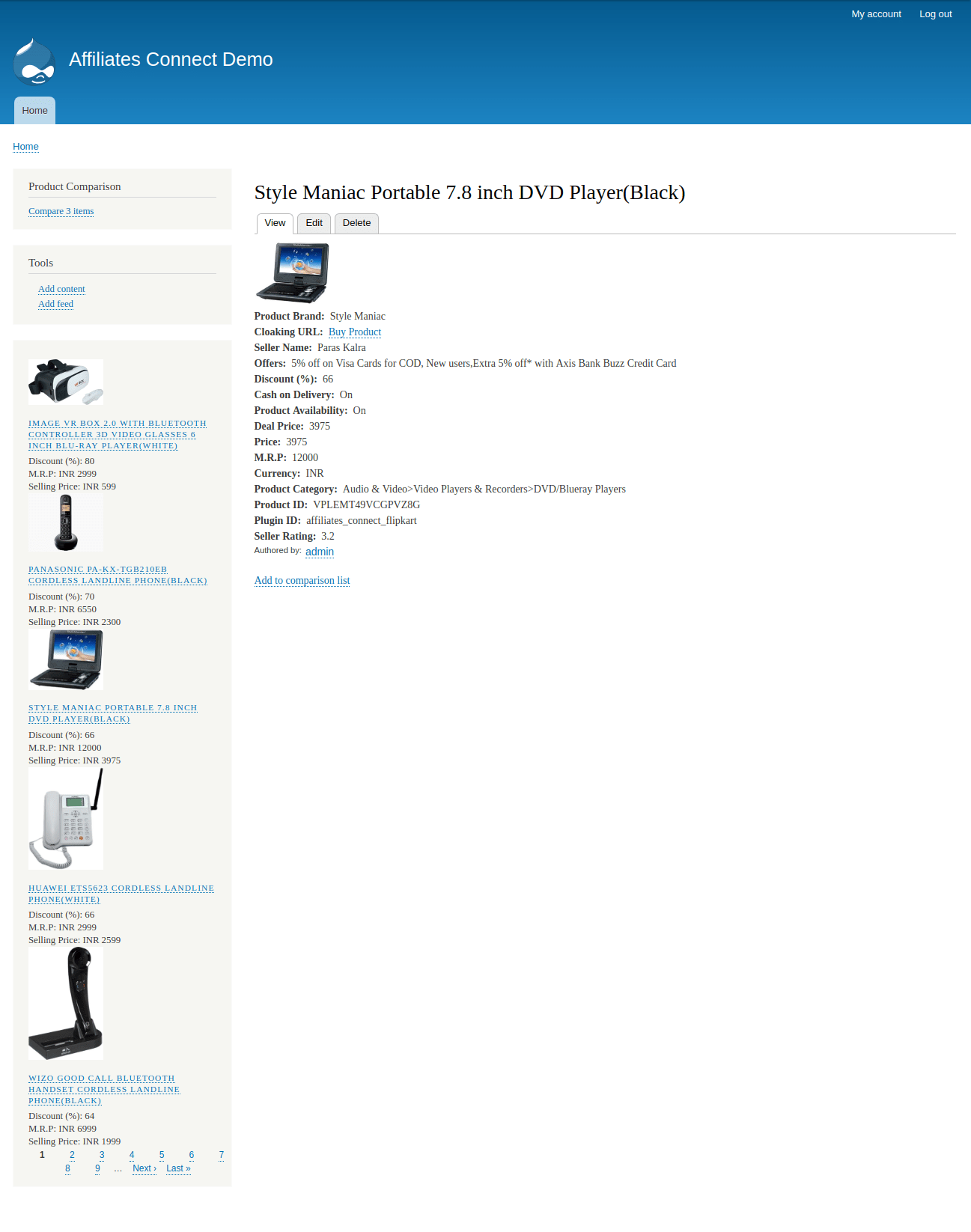
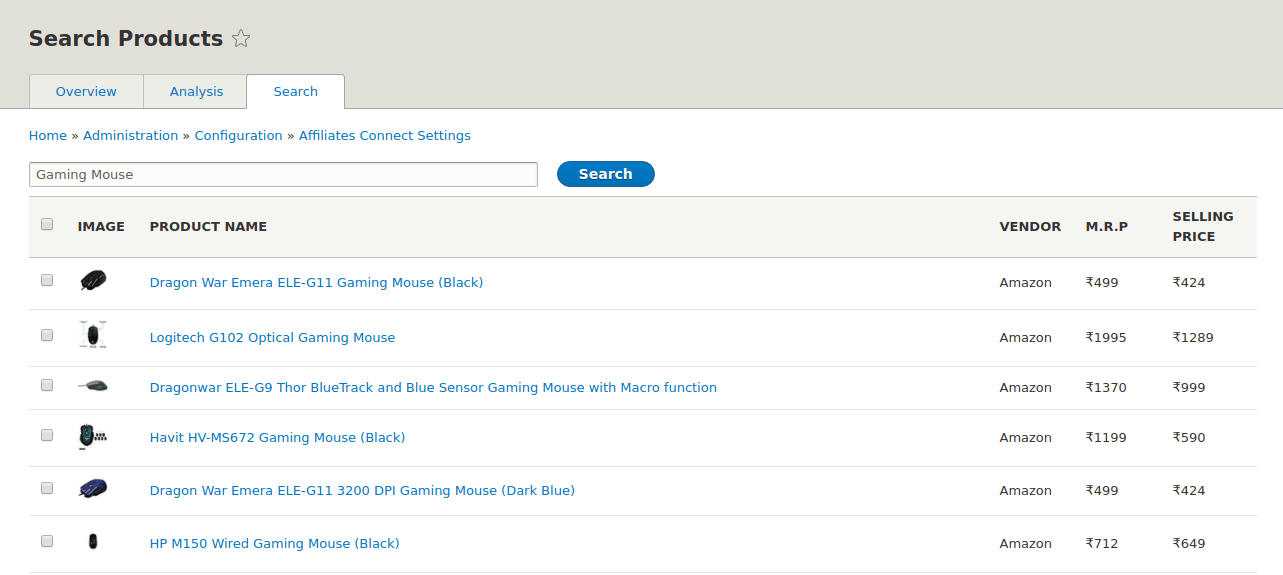
I am working on “Developing a “ Product Advertising API ” module for Drupal 8” - #7. The “Product Advertising API” which is renamed to “Affiliates Connect” module provides an interface to easily integrate with affiliate APIs or product advertising APIs provided by different e-commerce platforms like Flipkart, Amazon, eBay etc to fetch data easily from their database and import them into Drupal to monetize your website by advertising their products. If the e-commerce platforms don’t provide affiliate APIs, we will scrape the data from such platforms.
Progress
Some of the tasks accomplished in this week are-
- Scraper API is using feeds module for leveraging its functionalities and provide a generic scraper to scrape content. And by last week, I have already completed the Fetcher for my module and working on the pagination. The requirement of our module is to scrape all the relevant content related to the product, not just the content that is shown on the product overview page. But paginate (Feeds crawler) can only work on the product overview page. So to overcome this problem, I come up with new terms like “Inner Fetching/Scraping” and “Break Fetching”.
What Inner Fetching and Break Fetching do is, Through Inner Fetching, We scrape products link from the product overview page and goes to each product page and scrape its inner Content. We use Nodejs server for scraping hence, we sent multiple requests in parallel and append each product page HTML content to their respective overview page inside tag
A small demo video to explain this functionality can better understand it. Link to the video - Feeds Advance Crawler
-
After discussion with the mentors, We decided to provide this Fetcher as a separate module as it completely depends on the Feeds module and uses Feeds Extensible Parsers module for parsing using XPath HTML and QueryPath HTML parsers. In this way, people can better use its feeds crawling (That is not yet in D8 only in D7), inner fetching and Break fetching functionalities. It is completed and reviewed by dbjpanda and thedrupalkid. Link to the module - Feeds Advance Crawler
-
I have added the functional tests for the instantiation of the modules and its configs. It is reviewed by borisson_ , dbjpanda. Link to the issue - #2979801

- I have completed the Nodejs Scraper that is powering our Feeds Advance Crawler which all such features. It is still under review by shibasisp. Link to the Pull request - Node Scraper
Week 7 - Goals
-
Scraper API is using Nodejs Server for scraping and I have provided the static fetcher that fetches data from a static website. I need to provide the dynamic fetcher that fetches data from dynamic websites that use Angular and React lib to load content. For dynamic fetcher, I am using Nightmare and reasons for using nightmare is stated in this blog. Link to the blog post - GSoC Week 5 blog post
-
As we have to fetch millions of products so it is necessary to implement multiple user agents and proxy rotation to avoid blocking by the e-commerce websites.
-
Feeds Advance Crawler has a lot of configuration related to the mapping of fields with the correct source which will be difficult for users with no knowledge of QueryParser and Xpath. So I am working on providing some default preloaded configuration that can help him in creating the same configuration for other e-commerce websites.
Conclusion
Setting up default configuration for the user and provides the copy of that configuration in a single click similar to views can be a bit tough and requires some research. My previous research over Nodejs Scraper libs and speed tests can be a great help in developing dynamic scraper.