GSoC 2018 - Week - 6


Week 5 of the GSoC coding period is completed successfully and with this, the first evaluation is also completed successfully. GSoC (Google Summer of Code) is a global program focused on bringing more student developers into open source software development. Students work with an open source organization on a 3-month programming project during their break from school.
Project Abstract
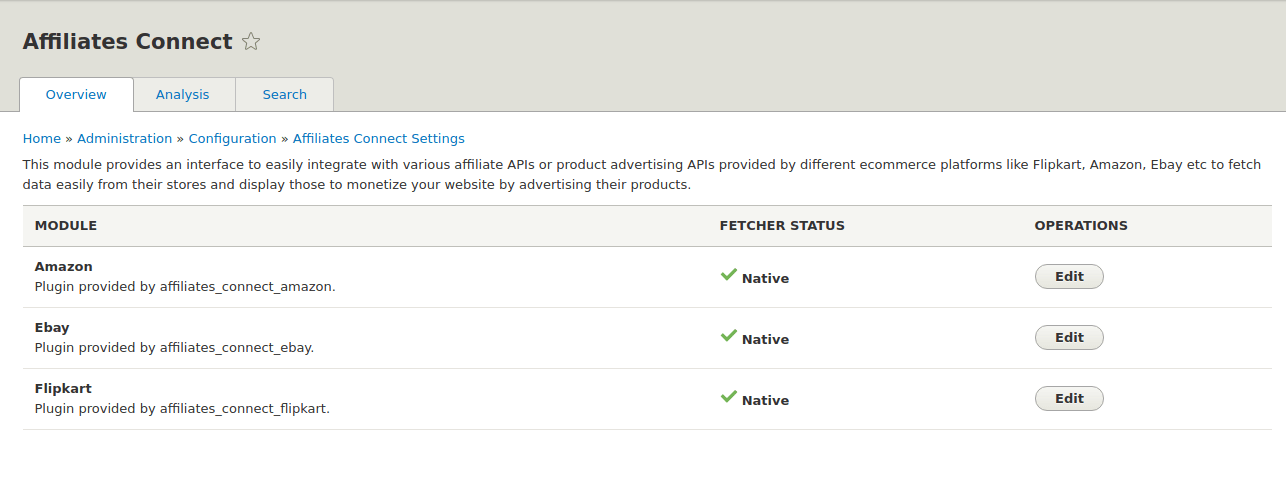
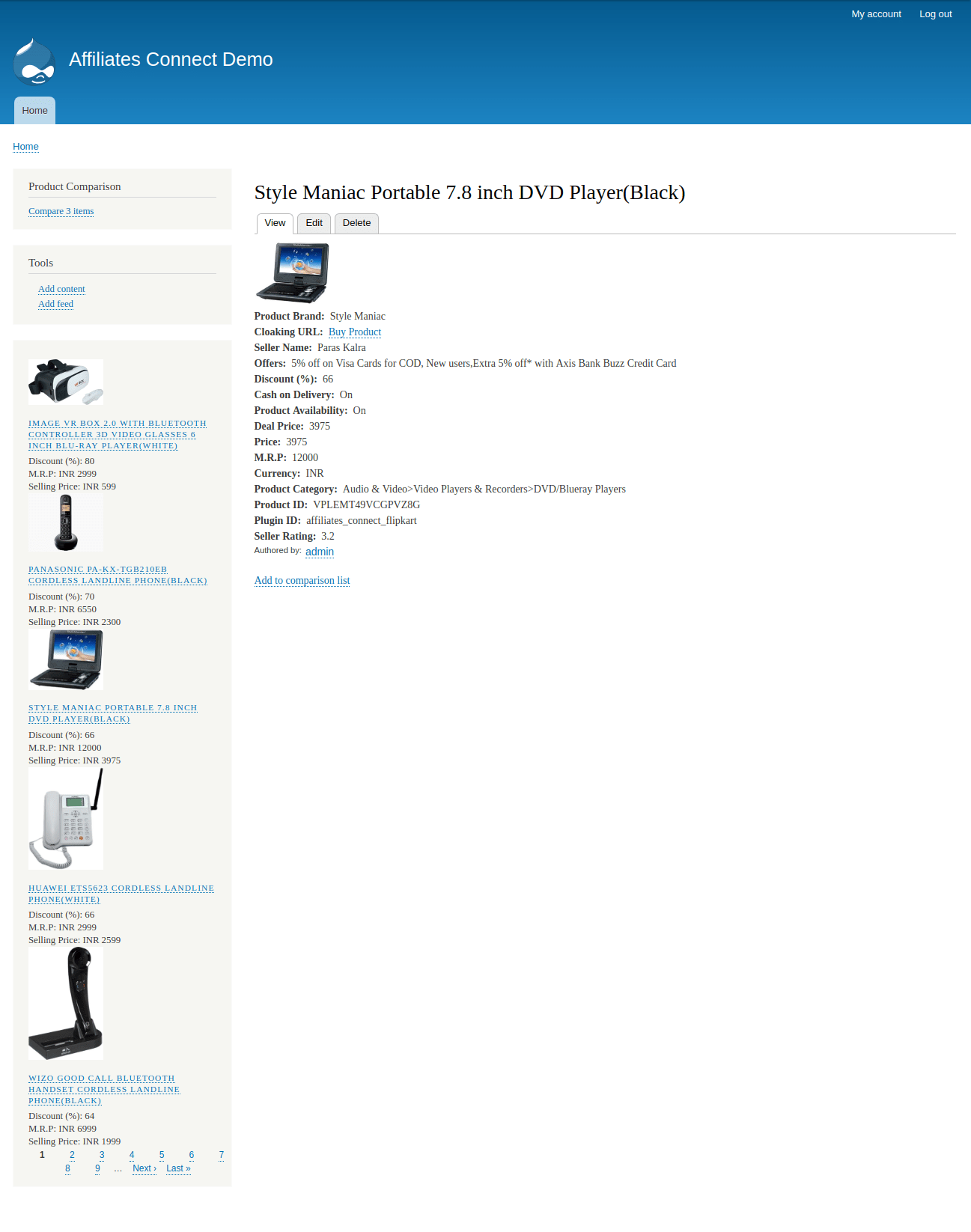
I am working on “Developing a “ Product Advertising API ” module for Drupal 8” - #7. The “Product Advertising API” which is renamed to “Affiliates Connect” module provides an interface to easily integrate with affiliate APIs or product advertising APIs provided by different e-commerce platforms like Flipkart, Amazon, eBay etc to fetch data easily from their database and import them into Drupal to monetize your website by advertising their products. If the e-commerce platforms don’t provide affiliate APIs, we will scrape the data from such platforms.
Progress
Some of the tasks accomplished in this week are-
- Native API for affiliates_connect_flipkart module is integrated but it needs to be reviewed. As we decided to create separate module for Flipkart and other E-commerce similar to Social Auth. I have used Batch API for fetching products data from Flipkart Affiliate API so that we can fetch all the products without facing any error else our request will get end due to exceeding max_execution_time in php. Its code is on Github, Link to the repo - affiliates_connect_flipkart

-
Fetcher for the Scraper API is complete. I have created two fetchers (StaticFetcher and DynamicFetcher). StaticFetcher and DynamicFetcher leveraging the power of Feeds module and save the content of URL in a temporary file which is further passed to the parser for parsing. This is under review and Link to the issue - #2979094
-
Fetcher will need the Nodejs Server as it is using Request lib for fetching the content from the URL and nightmare for websites which use JS to load DOM. It code is under this repo - Scraper
Week 6 - Goals
-
In this week, I will work on adding the pagination to the fetcher so that we can crawl and scrape multiple pages of the same category/type. In this way, we need not to create feeds for every single page which is impossible for anyone to do. Link to the issue - #2980450
-
I will also add functional tests for the checking whether the plugin (affiliates_connect_amazon) is instantiated properly after installing and other tests for the configuration form. Link to the issue - #2979801
-
I will try to complete the parser this week so that we can make good progress and complete the scraper part of the module.
Difficulties
-
Paginating every page is difficult but as feeds module is using Batch API and as in this issue - #2979249 it is mentioned - “Feeds asks the fetcher if there is something to fetch. With the returned result from the fetcher, it asks the parser to parse it. This is results in a number of items and for each item, Feeds asks the processor to process it. After all, items are processed, Feeds asks the parser again if it has more to parse. If so, this would result in a number of items again where each of them is passed to the processor. If the parser has nothing more to parse, Feeds will ask the fetcher again if it has more to fetch.” So It’s not going to be difficult.
-
Parser to parse the result of the fetcher and pass the result to the processor will be challenging.