GSoC 2018 - Week - 5


Week 4 of the GSoC coding period is completed successfully and with its completion, first evaluation period is also started. GSoC (Google Summer of Code) is a global program focused on bringing more student developers into open source software development. Students work with an open source organization on a 3-month programming project during their break from school.
Project Abstract
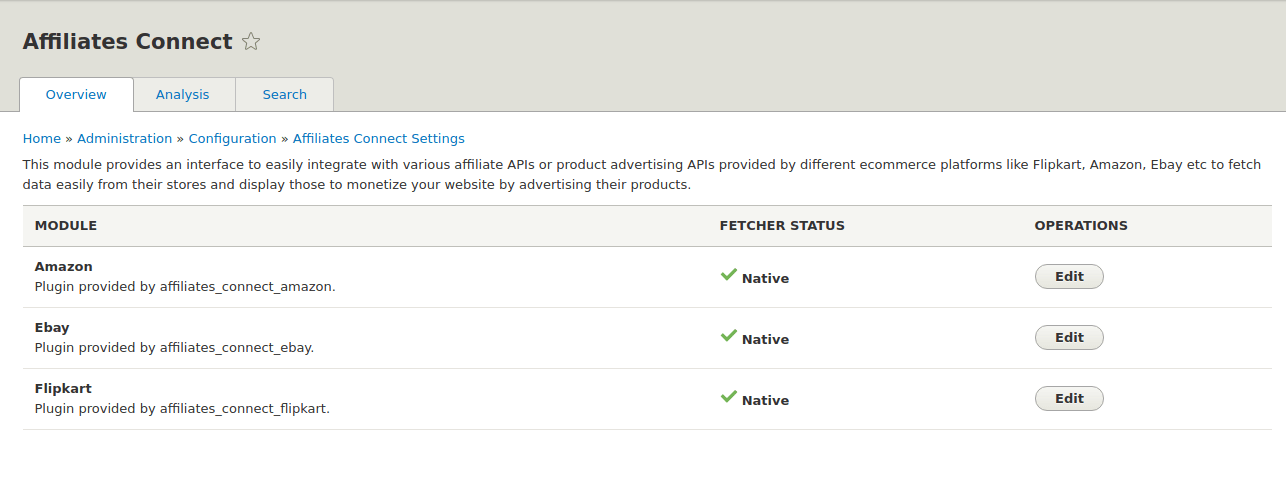
I am working on “Developing a “ Product Advertising API ” module for Drupal 8” - #7. The “Product Advertising API” which is renamed to “Affiliates Connect” module provides an interface to easily integrate with affiliate APIs or product advertising APIs provided by different e-commerce platforms like Flipkart, Amazon, eBay etc to fetch data easily from their database and import them into Drupal to monetize your website by advertising their products. If the e-commerce platforms don’t provide affiliate APIs, we will scrape the data from such platforms.
Progress
Some of the tasks accomplished before the first evaluation period, This post comprises of tasks completed from first week of GSoC to first evaluation period.
- The basic skeleton of the module is completed and reviewed by borisson_ , dbjpanda , gvso, thedrupalkid and other mentors. Link to the issue - #2975659

-
With the skeleton issue, The overview page which will show the different plugins enabled by the user and allow the users to configure plugins, is also completed.
-
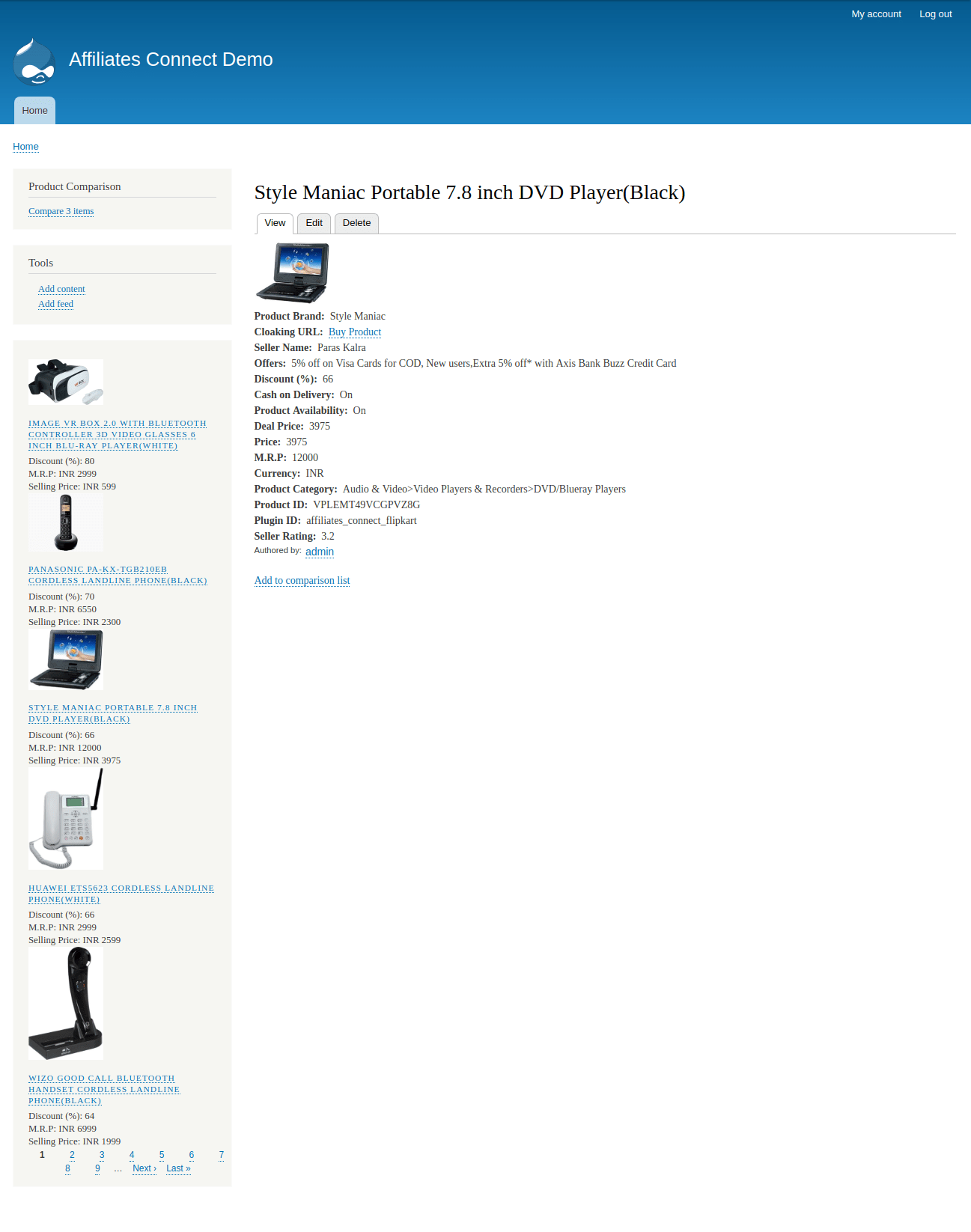
Content Entity for storing product’s data from various vendors is also completed and reviewed by borisson_ , dbjpanda , and other mentors. It is still under discussion whether to select nodes or content entities to store the data. I am thinking to use content entity for storing the product’s data and why I am using it, is also explained under this blog post - Where to store product’s data? Link to the issue - #2975642

- Functional Tests for verification of routes defined in the project as suggested by borisson_ is also completed and reviewed. It also included the functional tests for checking whether product’s data is submitted correctly by affiliates_product add form or not. Tests for deleting & editing the products are also completed under this issue. Link to the issue - #2977377
-
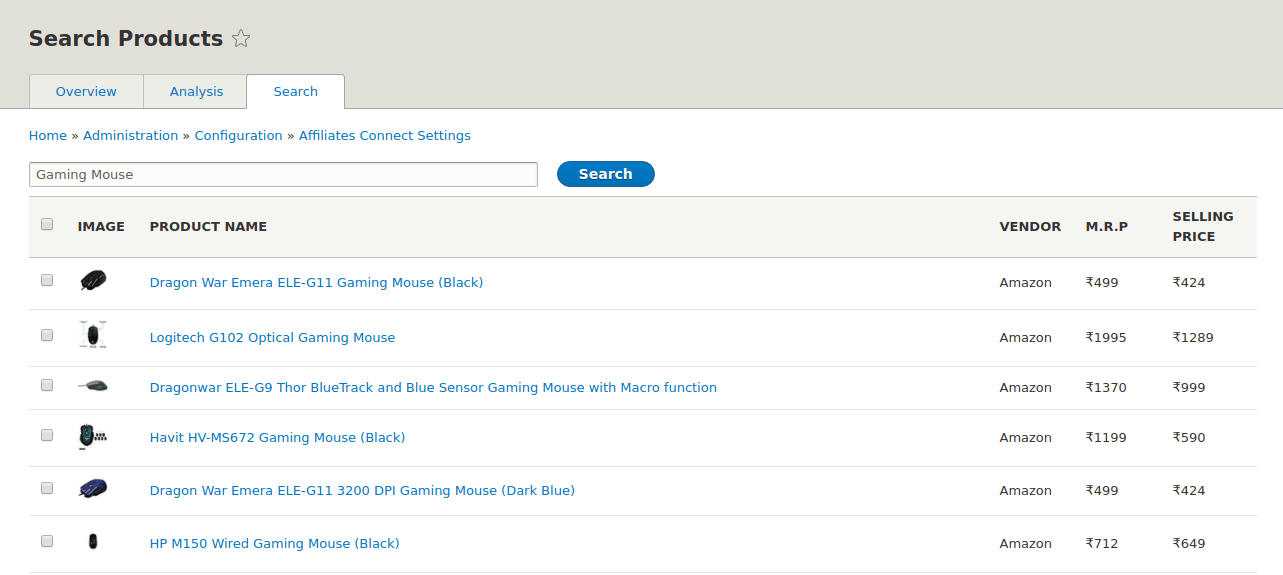
Native APIs provided by e-commerce sites only allow some percent of product’s data to be accessed. I am also working on Flipkart module in this repo from my previous studies in this repo. I will update my further work in the repo. We can’t fetch all the product’s data from any e-commerce sites so we need to write the scraper which does this task for us. For scraping, I am using Node.js to create scraper APIs.
-
For scraping millions of products from sites, we need to design the scraper that can give us high performance in terms of data and time, So i tested various nodejs libraries like request, zombie, puppeteer, phantom, and nightmare. I found that zombie is worst out of all, in case of websites which contain heavy javascript. Puppeteer and nightmare are taking equal time as phantomjs but less complex, fast and flexible to use. Request is best out of all but it is only for static websites unlike others which can also be used for websites which uses javascript to add content dynamically. Here are the speed benchmarks for the same.

Link to the repo - Scraping using node/scrapers-benchmarks
-
As discussed, We are using heterogeneous scraper so that we can use request/x-ray library for static websites and nightmare for dynamic websites.
-
Scraping Amazon websites using Nightmare is almost completed. Link to the repo - Scraping using node/Amazon
Week 5 - Goals
-
I have broken down the scraper API part into smaller issues, so it would be easy to implement and review. In this way, we can progress faster. I have added one issue to the issue queue. Link to the issue - #2979094
-
As discussed with mentors, We want something that can ease out the efforts at the end of the client side, So I am thinking to use Feeds module and utilize its feed import functionality. Feeds has config entity “feeds type” that allows user to use the type of fetcher, parser, processor and maps the fields of the selected proceessor. Once that feeds type is created, We can use it for multiple urls/categories (another entity defined as content entity for saving urls linked with feed types).
-
Feeds provides HTTPFetcher that use Guzzle for collecting response from the url entered by the user. As a part of this module, I am developing two Fetcher plugin named as StaticFetcher and DynamicFetcher. StaticFetcher is used to collect the response from static websites that will use Request/x-ray lib of Nodejs and DynamicFetcher for collecting the response from the dynamic websites (websites that use javascript to load the DOM) that will use Nightmare lib of Nodejs
-
Feeds provides parser for parsing and mapping the data collected from the fetcher part. So I am designing the separate parser that will use cheerio lib of Nodejs for parsing the data.
-
In this week, I am going to create the fetcher part. In this way, we can provide a user a generic scraper that can be configured as per the user requirement.